Experience Design in the Machine Learning Era
Notes for designers and data scientists who create together systems that learn from human behaviors

1. Introduction
Traditionally the experience of a digital service follows pre-defined user journeys with clear states and actions. Until recently, it has been the designer’s job to create these linear workflows and transform them into understandable and unobtrusive experiences. This is the story of how that practice is changing.
Over the last 6 months, I have been working in a rather unique position at BBVA Data & Analytics (D&A), a center of excellence in financial data analysis. My job is to make the design of user experiences reach a new frontier with the emergence of machine learning techniques. My responsibility — among other things — is to bring a holistic experience design to teams of data scientists and make it an essential part of the lifecycle of algorithmic solutions (e.g. predictive models, recommender systems). In parallel, I perform creative and strategic reviews of experiences that design teams produce (e.g. online banking, online shopping, smart decision making) to steer their evolution into a future of “artificial intelligence”. Practically, I boost the partnerships between teams of designers and data scientists to envision desirable and feasible experiences powered by data and algorithms.

Together we are defining a different kind of experience design with systems that learn from human behaviors. I believe this is a new practice because:
1. It creates new types of user experiences.
2. It redefines the relation between humans and machines.
3. It requests a tight partnership between designers and data scientists.
Let me describe each of these implications.
2. The new types of user experiences
Nowadays, the design of many digital services does not only rely on data manipulation and information design but also on systems that learn from their users. If you would open the hood of these systems, you would see that behavioral data (e.g. human interactions, transactions with systems) is fed as context to algorithms that generates knowledge. An interface communicates that knowledge to enrich an experience. Ideally, that experience seeks explicit user actions or implicit sensor events to create a feedback loop that will feed the algorithm with learning material.

Let me give you a practical example. Do you know how Spotify Discovery Weekly works?
Discovery Weekly is Spotify’s automated music recommendations “data engine” that brings two hours of custom-made music recommendations, tailored specifically to each Spotify user every Monday.

The Discover Weekly’s recommender system leverages the millions playlists that Spotify users create. It gives extra weight to the company’s own experts playlists and those with more followers. The algorithm attempts to augment a person’s listening habits with those with similar tastes. It does it in three main tasks:
- On one side, Spotify creates a profile of each user’s individualized taste in music, grouped into clusters of artists and micro-genres.
- On the other side, Spotify uses the billion of playlists to build a model of all the music they know about based on all the songs people group into playlists.
- Every week it connects the knowledge of music built with each user personal taste profile. Basically, if a favorite song tends to appear on playlists along with a third song not heard before, it will suggest that new song.
A typical Discover Weekly playlist recommends 30 songs, a big enough set to discover music that matches with a personal taste among other false positives. That experience provokes the curation of thousands of new playlists that are fed back into the algorithm a week after to generate new recommendations.
These feedback loop mechanisms typically offer ways to personalize, optimize or automate existing services. They also create opportunities to design new experiences based on recommendations, predictions or contextualization. At D&A, I came up with a first non-comprehensive list. Here is a walk-through:
2.1. Design for discovery
We have seen that recommender systems help discover the known unknown or even the unknown unknowns. For instance, Spotify helps discover music through a personalized experience defined on the match between an individual listening behavior and the listening behavior of hundreds of thousands of other individuals. That type of experience has at least three major design challenges.
First, recommenders systems have a tendency to create a “filter bubble” that limits suggestions (e.g. products, restaurants, news items, people to connect with) to a world that is strictly linked to a profile built on past behaviors. In response, data scientists must sometimes tweak their algorithms to be less accurate and add a dose of randomness to the suggestions.
Second, it is also good design practice to let an open door for users to reshape aspects of their profile that influence the discovery. I would call that feature “profile detox”. Amazon for example allows users to remove items that might negatively influence the recommendations. Imagine the customers purchase gifts for others and those gifts are not necessarily material for future personalized recommendations.
Finally, organizations that rely on subjective recommendation like Spotify now enlist humans to give more subjectivity and diversity to the suggested music. This approach of using humans to clean datasets or mitigate the limitations of machine learning algorithm is commonly called “Human Computation” or “Interactive Machine Learning” or “Relevance Feedback”.
2.2. Design for decision making
Data and algorithms also provide means to personalize decision making. For instance at D&A we developed advanced techniques to advise BBVA customers on their finance.

For example, we consider the temporal evolution of account balances to segment savings behaviors. With that technique we are able to personalize investment opportunities according to each customer’s capacity to save money.
This type of algorithms that leads to decision-making needs to learn to be more precise, simply because they often rely on datasets that only give a perspective of reality. In the case of financial advisory, a customer could operate multiple accounts with other banks preventing a clear view on on saving behaviors. It proved a good design practice to let users tell implicitly or explicitly about poor information. It is the data scientist’s responsibility to express the types of feedback that enrich their models and the designer’s job to find ways to make it part of the experience.
2.3. Design for uncertainty
Traditionally the design of computer programs follows a binary logic with an explicit finite set of concrete and predictable states translated into a workflow. Machine learning algorithms change this with their inherent fuzzy logic. They are designed to look for patterns within a set of sample behaviors to probabilistically approximate the rules of these behaviors (see Machine Learning for Designers by Patrick Hebron for a more detailed introduction to the topic). This approach comes with a certain degree imprecision and unpredictable behaviors. They often return some information on the precision of the information given.

For example the booking platform Kayak predicts the evolution of prices according to the analysis of historical prices changes. Its “farecasting” algorithm is designed to return confidence on whether it is a favorable moment to purchase a ticket (see Neal Lathia The Machine Learning Behind Farecast). A data scientist is naturally inclined to measure how accurately the algorithm predicts a value: “We predict this fare will be x”. That ‘prediction’ is in fact an information based on historical trends. Yet predicting is not the same as informing and a designer must consider how well such a prediction could support a user action: “Buy! this fare is likely to increase”. The ‘likely’ with an overview of the price trend is an example of a “beautiful seam” in the user experience, a notion coined by Mark Weiser at the time of the Xerox Palo Alto Research Center and further developed by Chalmers and MacColl as seamful design:
“Seamful design involves deliberately revealing seams to users, and taking advantage of features usually considered as negative or problematic”.
Seamful design is about exploiting failures and limitations to improve the experience. It is about improving the system allowing users to tell about poor recommendations. DJ Patil describes subtle techniques in Data Jujitsu.

Other types of machine learning algorithms communicate the seams with scores of precision and recall.
- The precision score communicates the ability to provide a result that exactly matches what’s desired.
- The recall score communicates the ability to provide a large set of possible good recommendations.
The ideal for an algorithm is to deliver high precision and recall scores. Unfortunately, precision and recall often work against each other. In many data analytics systems, there is often a need to take design decisions with the trade-off between precision versus recall. For instance, in Spotify Discovery Weekly, a design decision had to be taken to define the size of playlists according to the performance of the recommender system. A large playlist highlights the confidence of Spotify to deliver a rather large inventory of 30 songs, a wide-enough set to increase the opportunities for users to stumble on perfect recommendations.
2.4. Design for engagement
Today, what we read online is based on our own behaviors and the behaviors of other users. Algorithms typically score the relevance of social and news content. The aim of these algorithms is to promote content for higher engagement or send notifications to create habits. Obviously these actions taken on our behalf are not necessarily for our own interest.

Arguably, we entered into the attention economy, and major online services are fighting to hook people, grab their attention for as long as possible. Their business is to keep users active as long and frequently as possible on their platforms. This leads to the development of sticky, needy experiences that often play with emotions like Fear of Missing Out (FoMO) or other obsessions to dope the user engagement.
The actors of the attention economy use also techniques that promote addiction such as Variable Schedule Rewards. It is the exact same mechanisms as the ones used in slot machines. The resulting experience promotes the service’s interest (the casino) hooking people endlessly searching for the next reward. Our mobile phones have become those slot machines of notifications, alerts, messages, retweets, likes, that some of us check on an average 150 times per day if not more. Today designer can use data and algorithms to exploit cognitive vulnerabilities of people in their everyday lives. That new power raises the need for new design principles in the age of machine learning (see Aaron Weyenberg The ethics of good design: A principle for the connected age).
Yet the experience designed with machine learning algorithms do not need to be the one of a casino.
2.5. Design for time well spent
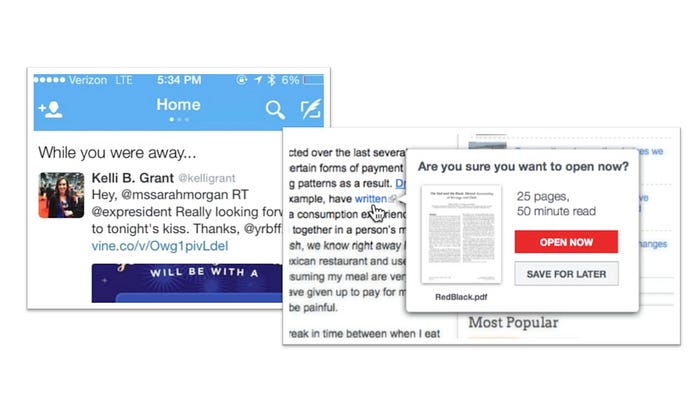
There are opportunities to design a radically different experience than engagement. Indeed, an organization like a bank has the advantage of being a business that runs on data and does not need customers to spend the maximum amount of time with their services. Tristan Harris Time Well Spent movement is particularly inspiring in that sense. He promotes the type of experience that use data to be super-relevant or be silent. The type of technology to protect the user focus and to be respectful of people’s time. The Twitter “While you were away…” is a compelling example of that practice. Other services are good at suggesting moments to engage with them. Instead of measuring user retention, that type of experience focuses on how relevant the interactions are.
2.6. Design for peace of mind
Data scientists are good in detecting normal behavior and abnormal situations. At D&A, we are working to promote a peace of mind to BBVA customers with mechanisms that gives a general awareness when things are fine and that trigger more detailed information on abnormal situations. More generally, we believe current generation of machine learning brings new powers to society, but also increases the responsibility of their creators. Algorithmic bias exists and may be inherent to the data sources. In consequence, there is a particular need to make algorithms more legible for people and auditable by regulators to understand their implications. Practically, this means knowledge that the an algorithm produces should safeguard the interest of their users and the results of the evaluation and the criteria used should be explained.
Additional related terrains of experience design are:
- Design for fairness
- Design for conversation
- Design for automation
And probably many more.
3. The new relation between humans and machines
In the previous section we have seen that the experiences powered by machine learning are not linear or based on static business and design rules. They evolves according to human behaviors with constantly updating models fed by streams of data. Each product or service becomes almost like a living, breathing thing. Or as people at Google would say: “It’s a different kind of engineering”. I would argue that it is also a different kind of design. For instance, Amazon explains Echo’s braininess as a thing that “continually learns and adds more functionality over time”. This description highlights the need to design the experience for systems to learn from human behavior.

Consequently, beyond considering the first contact and the onboarding experience, that type of product or service requires considerations on their use after 1 hour, 1 day, 1 year, etc. If you look at the promotional video of the Edyn garden sensor you will notice the evolution of the experience from creating new habits for taking care of a garden to communicating the unknown unknowns about plants, to convey peace of mind on the key metrics, and to guarantee time well spent with some level of watering automation.
That type of data product requires a responsible design that considers moments when things start to disappoint, embarrass, annoy or stop working or being useful. The design of the “offboarding experience” could become almost as important as the “onboarding experience”. For instance, allegedly a third of the Fitbit users stop wearing the device within 6 months. What happens to these millions of abandoned connected objects? What happens to the data and intelligence on the individual they produced? What are the opportunities to use them in different experiences?

There are new ways to imagine the relation after a digital break-up with a product. Digital services work on an increasingly vast ecosystem of things and channels but user data have a tendency to be more centralized. Think about the notion of portable reputation that allows people to use a service based on the relation measured with another service.
Looking a bit further into the near future, the recent breakthrough in Natural Language Processing, Knowledge Representation, Voice Recognition and Nature Language Production could create more subtle and stronger relations with machines. In a few iterations, Amazon Echo might start to be much more nurturing. A potential evolution that anthropologist Genevieve Bell foresees a shift from human-computer interactions to human-computer relationships in The next wave of AI is rooted in human culture and history:
“So the frame there is not about recommendations, which is where much of AI is now, but is actually about nurture and care. If those become the buzzwords, then you sit in this very interesting moment of being able to pivot from talking about human-computer interactions to human-computer relationships.”
— Genevieve Bell
In this section we have seen that algorithms are getting closer to our everyday lives and that data provide a context for an evolving relationship. The implications of that evolution require most intense collaboration between design and data science.
4. The partnership between designers and data scientists
My experience so far envisioning experiences with data and algorithms shows that it is a different practice from current human-centered design. At D&A, the role of data scientists has been elevated from reactive model and A/B test developers to proactive partners who think about the implications of their work. Our singular data science teams breaks into sub-teams that partner more directly with engineers, designers, and product managers.
When design meets science
At the moment of shaping an experience, we exploit thick data, the qualitative information that provides insights on people’s lives (see Tricia Wang Why Big Data Needs Thick Data), big data from the aggregated behavioral data of millions of people and the small data that each individual generates.
Classically, designers focus on defining the experience of the service, feature or product. They nest the concept within the larger ecosystem that relates to it. Data scientists develop the algorithms that will support that experience and measure it with A/B testing.
The first few weeks in my role at D&A, I found designers and data scientists often stuck in deadlocked exchanges that typically sounded like this:
Designer: Hello! What can you, your data and algorithms tell me?
Data scientist: Well… What do you want to know?
The main issue was the lack of shared understanding of each other’s practice and objectives. For instance, designers transform a context into a form of experience. Data scientists transform a context with data and models into knowledge. Designers often adopt a path that adapts to a changing context and new appreciations. Data scientists employ processes similar to humber-center design but are more mechanical and less organic. They strictly follow the scientific methods with its cyclical processes of constant refinement.
A properly formulated research question helps define the hypothesis and the types of models to develop in the prototyping phase. The models are the algorithms that get evaluated before they are deployed to production into what we call at D&A a “data engine”. Whenever the experience supported by the “data engine” does not perform as expected, the problem needs to be reformulated to continue the cyclical process of constant refinement.

4.1. The touchpoints
The scientific method is similar to any design approach that forms and makes new appreciations as new iterations are necessary. Yet, it is not an open-ended process. It has a clear start and end but no definite timeline. Data scientist Neal Lathia argues that “cross-disciplinary work is hard, until you’re speaking the same language”. Additionally, I believe designers and data scientists must immerse themselves in the other’s practice to build a common rhythm. So far, I codified several important touchpoints for designers and data scientists to produce a meaningful user experience powered by algorithms. They must:
- Co-create a tangible vision of the experience and solution with priorities, goals and scope
- Assess any assumption with insights from quantitative exploration, desk research and field research.
- Articulate the key questions from the vision and the research. Is the team asking the right questions and are the answers algorithms could give actionable?
- Understand all the limitations of the data model that gives answers.
- Specify the success metrics for a desirable experience and define them before the release of a test. The validation phase acts as stopping point and it must be defined as part of the objectives of the project (e.g. improve the recall of the recommendations by 5%, detect 85% of customer who are about to default).
- Evaluate the impact of the data engine on the user experience. As stated by Neal Lathia, it is particularly hard for data scientists to work “offline” on an algorithm and measure improvements that will correlate with improvements in the actual user experience.
This intertwined collaboration illustrates a new type of design that I am trying to articulate. In a recent article Harry West CEO at frog suggested the term ‘design of system behavior’:
“Human-centered design has expanded from the design of objects (industrial design) to the design of experiences (adding interaction design, visual design, and the design of spaces) and the next step will be the design of system behavior: the design of the algorithms that determine the behavior of automated or intelligent systems”
— Harry West
4.2. A vision-driven partnership
So far I have argued that “living experiences” emerge at the crossroad of data science and design. An indispensable first step is for designers and data scientists is to establish a tangible vision and its outcomes (e.g. experience, solution, priorities, goals, scope and awareness of feasibility). Airbnb Director of Product Jonathan Golden calls that a vision-driven product management approach:
“Your company vision is what you want the world to look like in five-plus years. Outcomes are the team mandates that will help you get there.”
— Jonathan Golden
However, that conceptualization phase requires that visions live not just as flat perfect things for board room PowerPoint. Therefore, one of my approaches is to engage the design/science partnership to produce Design Fictions. It has similarities with Amazon’s Working Backwards’ process as described by their CTO Werner Vogels:
“You start with your customer and work your way backwards until you get to the minimum set of technology requirements to satisfy what you try to achieve. The goal is to drive simplicity through a continuous, explicit customer focus.”

Design Fiction aims at making tangible the evolution of technologies, the language used to describe them, the rituals, the magic moments, the frustrations, and why not the “offboarding experience”. It helps the different stakeholders of a project to engage with essential questions to understand what the desired experience means and why the team should build it. What are the implications of purchasing that next generation Garden Sensor? What can you do with it? What aren’t you allowed to do? What won’t you do anymore? How does a human interact with that technology the first time, and then routinely after a month, one year or more? Creative and tangible answers to these questions can come to life before a project even starts with the creation of fictional customer reviews, user manual, press release, ads. That material is a way to bring the future to present or as we say at the Near Future Laboratory:
“The Design Fictions act as a totem for discussion and evaluation of changes that could bend visions of the desirable and planning of what is necessary.”
At D&A, this means that I gather data scientists and designers with the objective of creating a tangible vision of their research agenda. First, we first map the ongoing lines of investigations.

Then we project their evolution into 2 or 3 iterations wondering: What would the potential resulting technology look like? Where could it be used? Who would use it and for what type of experience? Each participant uses the template of a fictional ad to tell stories with practical answers to these questions. Together we group them into future concepts.

We collect all the material and promote the most promising concepts. After that, we share these results internally in series of paper and video advertisements that describe the main features, attributes, characteristics of the experience from our point of view (the possible) and the user’s point of view (the desirable).

This type of fictional material allows both designers and data scientists to feel and get a practical understanding of the technology and its experience. The results help build credibility, enlist support, counter skepticism, create momentum and share a common vision. Finally, the feedback of people with different perspectives allows to anticipate opportunities and challenges.
5. The design characteristics
In this article, I have argued that, with the advance of machine learning and “artificial intelligence” (AI), it becomes the responsibility of both designers and data scientists to understand how to shape experiences that improve lives. Or as Greg Borenstein argues in Power to the People: How One Unknown Group of Researchers Holds the Key to Using AI to Solve Real Human Problems:
“What’s needed for AI’s wide adoption is an understanding of how to build interfaces that put the power of these systems in the hands of their human users.”
That type of design of system behavior represents a future in the evolution of human-centered design. So far in my journey of creating meaningful experiences in the machine learning era, I can articulate the following characteristics:
Feedback: Data is the lifeblood of the user experience with systems that learn. Guarantee that systems are properly fed with carefully crafted feedback loop mechanisms.
Relationship: The combination of data and learning algorithms can trigger an evolution of multiple experiences. Plan the relationship between humans and the machine that learns for instance creating habits aligned with people’s interest, finding the known unknown, discovering the unknown unknowns, communicating a certain peace of mind, or valuing time well spent. Additionally, prepare the “offboarding experience” for moments in the relationship when things start to disappoint, embarrass, annoy or stop working or being useful.
Seamfulness: Consider bringing both the power and imperfections of algorithms to the surface as part of the experience. For example, predicting is not the same as informing and a designer must consider how well the level of uncertainty in a prediction could support a user action.
This is an extended transcript of a talk I gave at the Design Wednesdays event at the BBVA Innovation Center in Madrid on September 21, 2016 originally published in BBVA Data & Analytics’ blog https://www.bbvadata.com/experience-design-in-the-machine-learning-era/. Many thanks to the BBVA Design team for their invitation and to the attendees for their interest.
Thanks to Leonardo Baldassini, Neal Lathia and Nicolas Nova for their feedback.
